Preprints
We fine-tune LMs with RL to rewrite documents into better representations for a target black-box retriever, allowing smaller retrievers to match or beat larger retrievers on code and visual document retrieval tasks.
Selected Publications
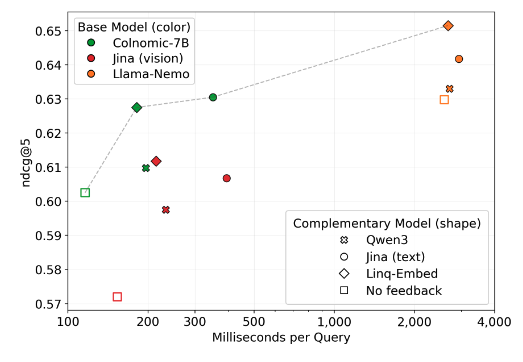
GQR refines a primary retriever's query embedding at test time using guidance from a lightweight auxiliary retriever of a different modality, matching larger models while being up to 14x faster and 54x lighter.
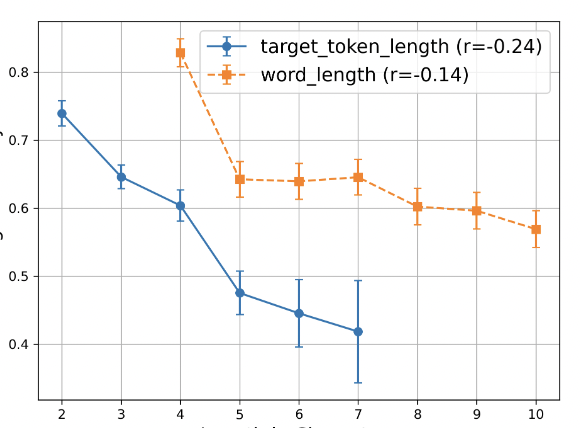
We study character-level tasks in LMs and the effect of subword tokenization. We find that tokenization features are not correlated with performance on many character-level tasks, contrary to the common perception. We publish a benchmark for future work and reproduction.
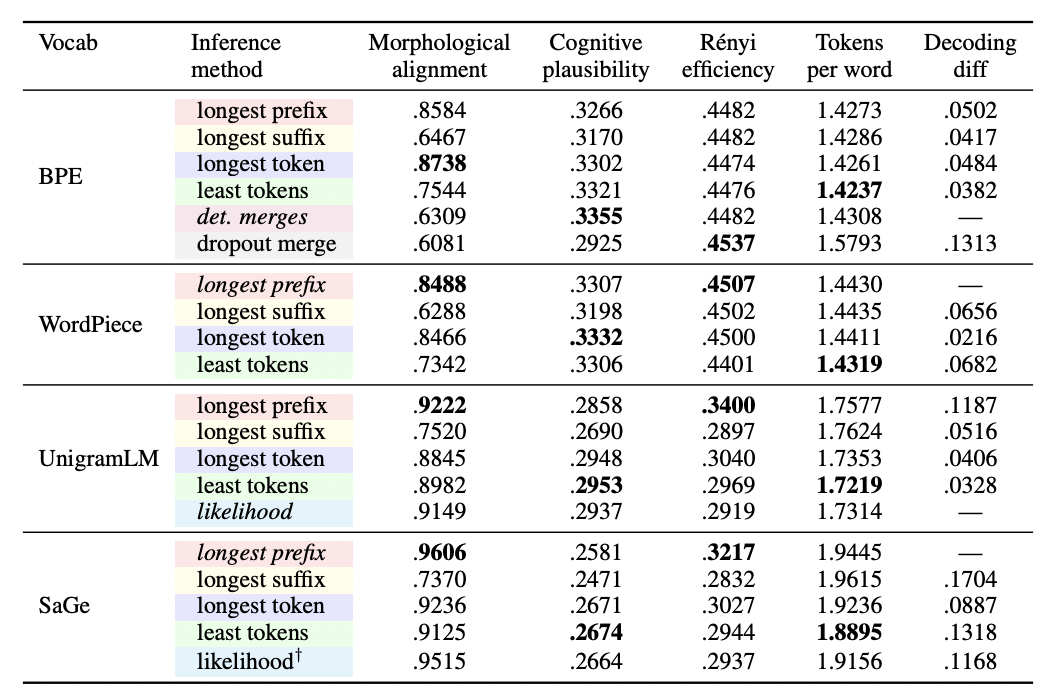
We show that for many subword tokenizers, vocabulary construction and tokenization inference are separable components. Using a new intrinsic benchmark, we evaluate popular tokenizers and find that simple greedy inference performs surprisingly well across tokenization algorithms.
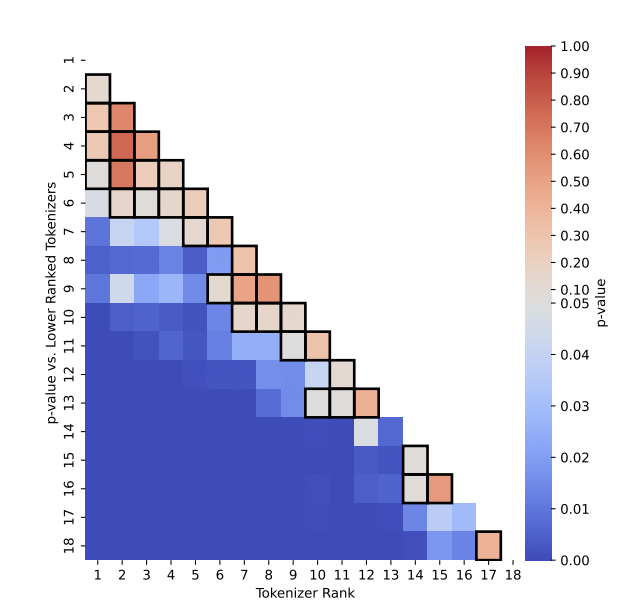
Introduces PathPiece, a tokenizer that minimizes token count, and uses it to show empirically that fewer tokens do not necessarily lead to better language models. The results suggest that pre-tokenization and vocabulary construction often matter more than compression rate alone.